5.6. 处理器执行程序指令
指令执行分为几个阶段。不同的架构实现的阶段数不同,但大多数架构将指令执行的获取、解码、执行和写回阶段分为四个或更多个独立阶段。在讨论指令执行时,我们重点关注这四个执行阶段,并使用 ADD 指令作为示例。我们的 ADD 指令示例的编码如 图 1 所示。

图 1. 三寄存器操作的示例指令格式。该指令以二进制编码,其位的子集对应于指令不同部分的编码:操作(操作码)、两个源寄存器(操作数)和用于存储操作结果的目标寄存器。该示例显示了以此格式对 ADD 指令的编码。
要执行一条指令,CPU 首先从内存中将下一条指令提取到专用寄存器,即指令寄存器 (IR) 中。要提取的指令的内存地址存储在另一个专用寄存器,即程序计数器 (PC) 中。PC 跟踪下一条要提取的指令的内存地址,并在执行提取阶段时递增,以便存储下一条指令的内存地址的值。例如,如果所有指令都是 32 位长,则 PC 的值增加 4(每个字节,8 位,都有一个唯一的地址)以存储紧接着被提取的指令的内存地址。独立于 ALU 的算术电路会增加 PC 的值。PC 的值也可能会发生变化。例如,某些指令会跳转到特定地址,例如与循环、if-else 或函数调用的执行相关的地址。 图 2 显示了执行的获取阶段。
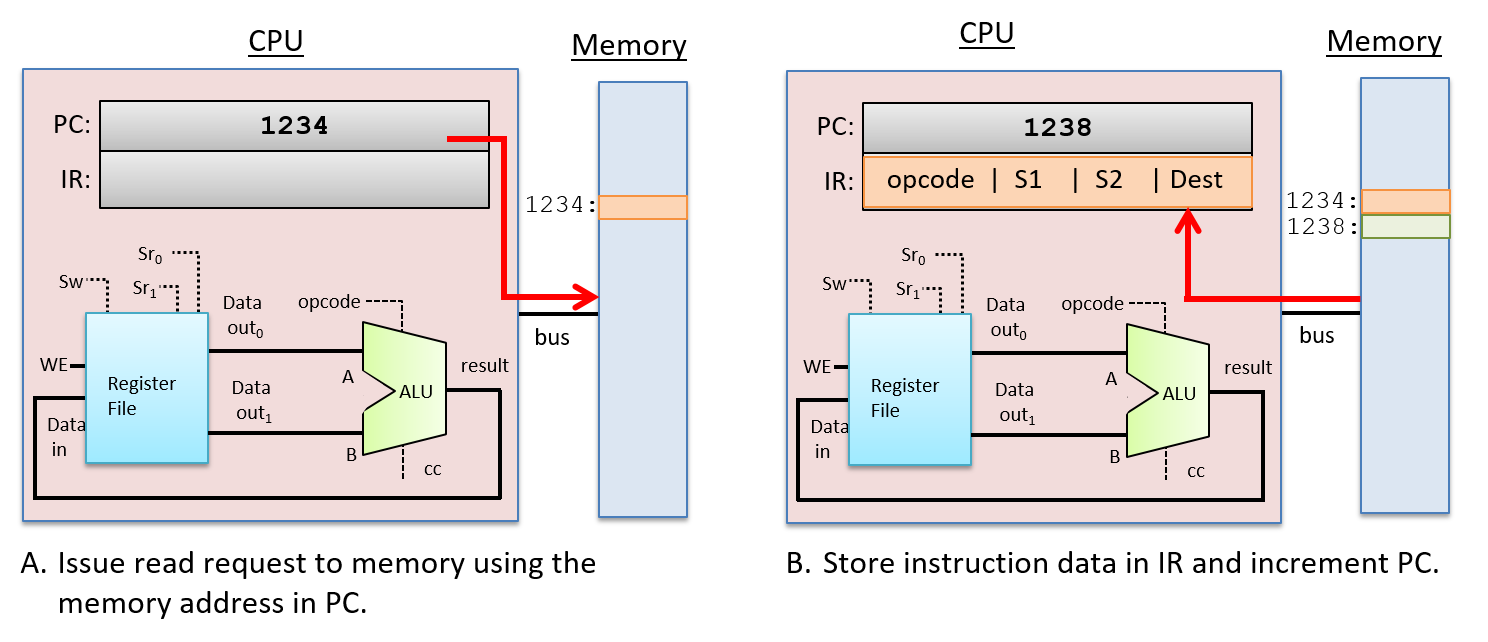
图 2. 指令执行的提取阶段:PC 寄存器中存储的内存地址值处的指令从内存中读取并存储到 IR 中。PC 的值也在此阶段结束时递增(如果指令为 4 个字节,则下一个地址为 1238;实际指令大小因架构和指令类型而异)。
在获取指令后,CPU 将存储在 IR 寄存器中的指令位解码为四个部分:指令的高位编码操作码,指定要执行的操作(例如 ADD、SUB、OR 等),其余位分为三个子集,指定两个操作数源和结果目标。在我们的示例中,我们将寄存器用于源和结果目标。操作码通过输入到 ALU 的线路发送,源位通过输入到寄存器文件的线路发送。源位被发送到两个读取选择输入(Sr0 和 Sr1),它们指定从寄存器文件读取哪些寄存器值。解码阶段如图 3 所示。
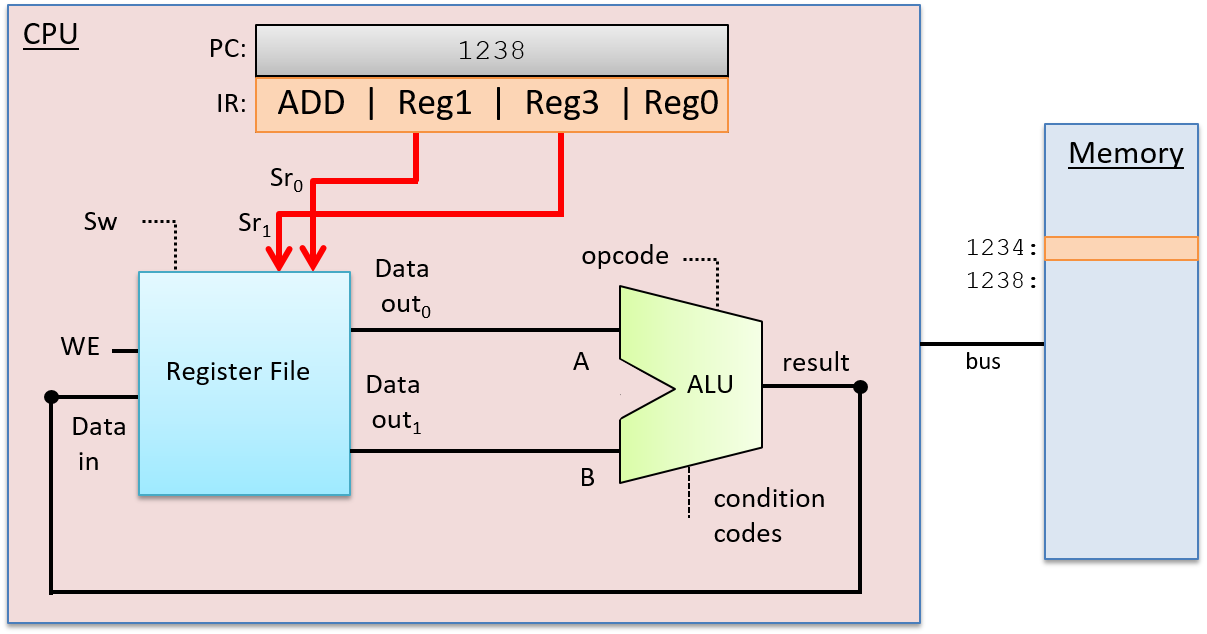
图 3. 指令执行的解码阶段:将 IR 中的指令位分解为组件,并将它们作为输入发送到 ALU 和寄存器文件。IR 中的操作码位被发送到 ALU 选择输入,以选择要执行的操作。IR 中的两组操作数位被发送到寄存器文件的选择输入,以选择从中读取操作数值的寄存器。IR 中的目标位在 WriteBack 阶段被发送到寄存器文件。它们指定将 ALU 结果写入哪个寄存器。
在解码阶段确定要执行的操作和操作数来源之后,ALU 在下一阶段即执行阶段执行操作。ALU 的数据输入来自寄存器文件的两个输出,其选择输入来自指令的操作码位。这些输入通过 ALU 传播以产生将操作数值与操作相结合的结果。在我们的示例中,ALU 输出将存储在 Reg1 中的值与存储在 Reg3 中的值相加的结果,并输出与结果值相关联的条件码值。执行阶段如图 4 所示。
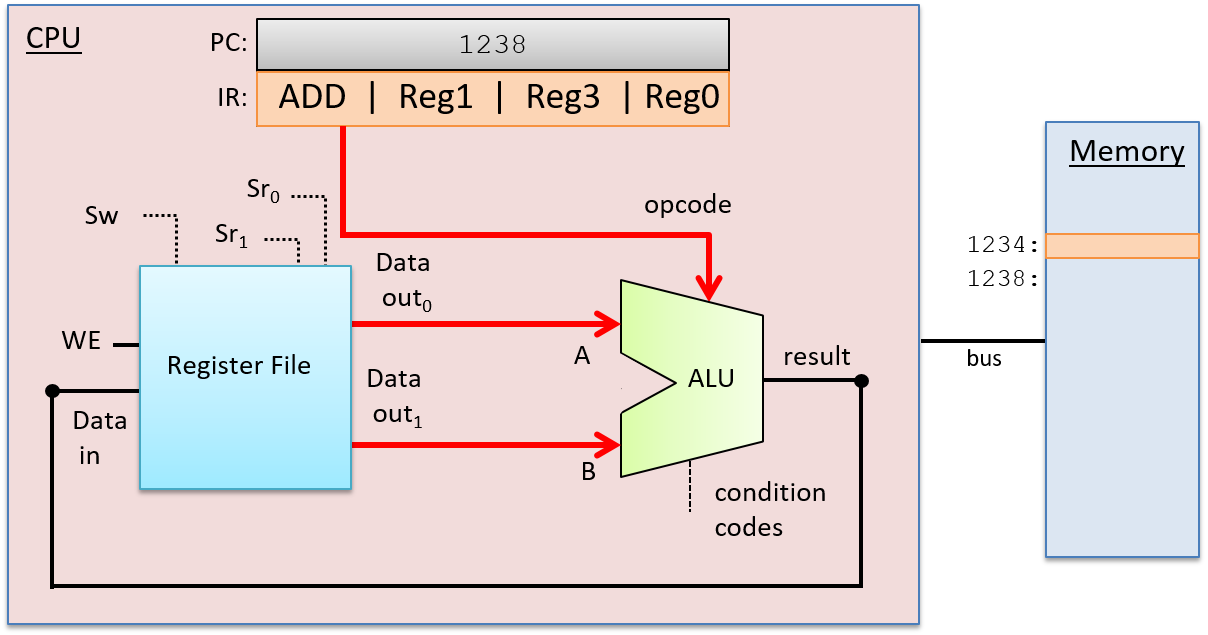
图 4. 指令执行的执行阶段:ALU 对其输入值(来自寄存器文件输出)执行指定的操作(来自指令操作码位)。
在 WriteBack 阶段,ALU 结果存储在目标寄存器中。寄存器文件在其 Data in 输入上接收 ALU 的结果输出,在其写选择 (Sw) 输入上接收目标寄存器(来自 IR 中的指令位),在其 WE 输入上接收 1。例如,如果目标寄存器是 Reg0,则 IR 中编码 Reg0 的位将作为 Sw 输入发送到寄存器文件以选择目标寄存器。ALU 的输出作为 Data in 输入发送到寄存器文件,并且 WE 位设置为 1 以启用将 ALU 结果写入 Reg0。WriteBack 阶段如图 5 所示。
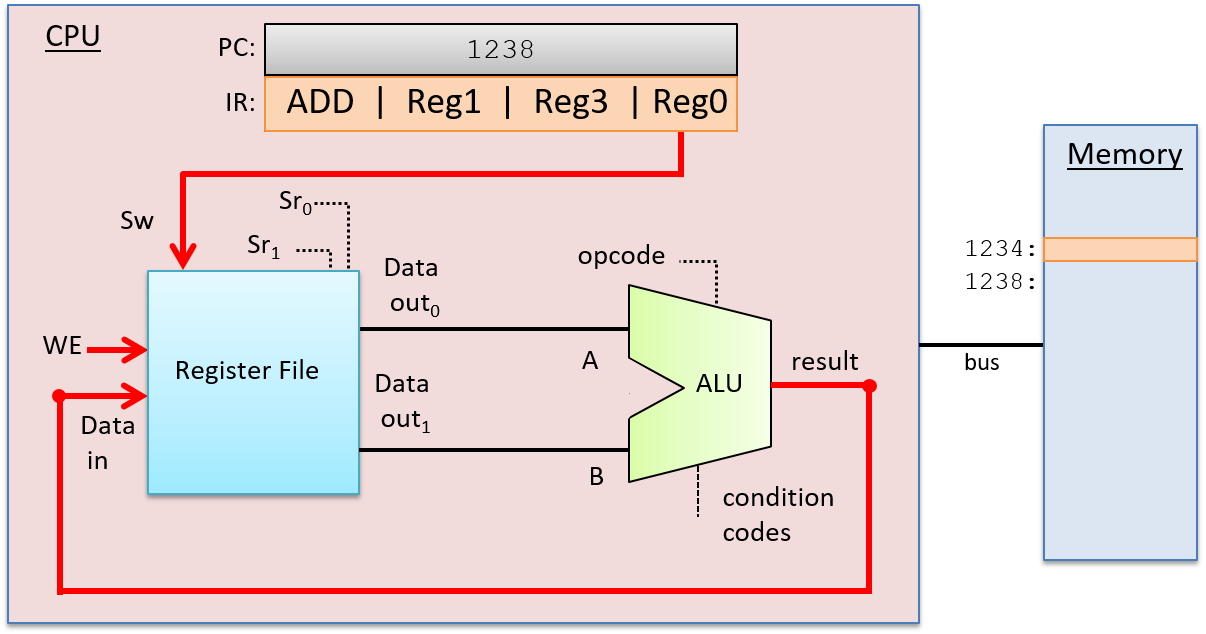
图 5. 指令执行的 WriteBack 阶段:执行阶段的结果(ALU 的输出)被写入寄存器文件中的目标寄存器。ALU 输出是寄存器文件的 Data in 输入,指令的目标位进入寄存器文件的写选择输入 (Sw),WE 输入设置为 1,以便将 Data in 值写入指定的目标寄存器。
5.6.1. 时钟驱动执行
时钟驱动 CPU 执行指令,触发每个阶段的开始。换句话说,CPU 使用时钟来确定与每个阶段相关的电路的输入何时可供电路使用,并控制电路的输出何时代表一个阶段的有效结果,并可用作执行下一阶段的其他电路的输入。
CPU 时钟测量离散时间,而不是连续时间。换句话说,对于后续的每个时钟滴答,存在一个时间 0,后跟一个时间 1,后跟一个时间 2,依此类推。处理器的 时钟周期时间 测量每个时钟滴答之间的时间。处理器的 时钟速度 (或 时钟速率)是 1/(时钟周期时间)。它通常以兆赫 (MHz) 或千兆赫 (GHz) 为单位。1 MHz 时钟速率每秒有 100 万个时钟滴答,而 1 GHz 时钟速率每秒有 10 亿个时钟滴答。时钟速率是衡量 CPU 运行速度的指标,是 CPU 每秒可执行的最大指令数的估计值。例如,在像我们的示例 CPU 这样的简单标量处理器上,2 GHz 处理器可能实现每秒 20 亿条指令(或每纳秒 2 条指令)的最大指令执行率。
虽然增加单台机器的时钟频率会提高其性能,但时钟频率本身并不是比较不同处理器性能的有意义的指标。例如,某些架构(如 RISC)执行指令所需的阶段比其他架构(如 CISC)要少。在执行阶段较少的架构中,较慢的时钟可能产生与时钟频率更快但执行阶段较多的架构相同的每秒完成指令数。然而,对于特定的微处理器,将其时钟速度加倍将大致使其指令执行速度加倍。
时钟频率和处理器性能
从历史上看,提高时钟频率(以及设计更复杂、更强大的微架构以便由更快的时钟驱动)一直是计算机架构师提高处理器性能的一种非常有效的方法。例如,1974 年,英特尔 8080 CPU 的运行速度为 2 MHz(时钟频率为每秒 200 万个周期)。1995 年推出的英特尔奔腾 Pro 的时钟频率为 150 MHz(每秒 1.5 亿个周期),2000 年推出的英特尔奔腾 4 的时钟频率为 1.3 GHz 或(每秒 13 亿个周期)。2000 年代中后期,随着 IBM z10 等处理器的时钟频率达到 4.4 GHz,时钟频率达到了顶峰。
然而,如今,由于处理更快时钟的散热问题,CPU 时钟频率已达到极限。此限制称为 功率墙。功率墙导致从 2000 年代中期开始开发多核处理器。多核处理器每个芯片有多个“简单”CPU 内核,每个内核由一个时钟驱动,其速率与上一代内核相比没有增加。多核处理器设计是一种无需增加 CPU 时钟频率即可提高 CPU 性能的方法。
时钟电路
时钟电路使用振荡器电路来生成非常精确且有规律的脉冲模式。通常,晶体振荡器产生振荡器电路的基频,时钟电路使用振荡器的脉冲模式输出交替的高低电压模式,该模式对应于 1 和 0 二进制值的交替模式。图 6 显示了生成 1 和 0 的规则输出模式的示例时钟电路。
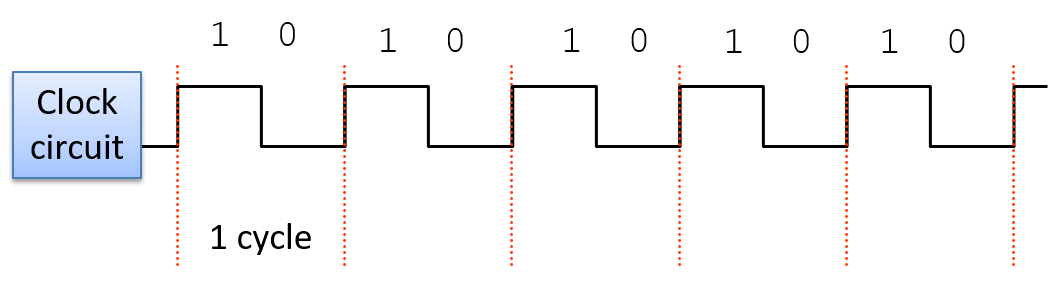
图 6. 时钟电路的 1 和 0 的常规输出模式。每个 1 和 0 序列构成一个时钟周期。
时钟周期(或滴答)是时钟电路模式中的 1 和 0 子序列。从 1 到 0 或从 0 到 1 的转换称为时钟边沿。时钟边沿触发 CPU 电路的状态变化,从而驱动指令的执行。时钟上升沿(在新的时钟周期开始时从 0 到 1 的转换)表示输入值已准备好进行指令执行阶段的状态。例如,上升沿转换表示 ALU 电路的输入值已准备就绪。当时钟的值为 1 时,这些输入会通过电路传播,直到电路的输出准备好为止。这称为电路的传播延迟。例如,当时钟信号为 1 时,ALU 的输入值会通过 ALU 操作电路传播,然后通过多路复用器,从而为组合输入值的操作从 ALU 产生正确的输出。在下降沿(从 1 到 0 的转换),该阶段的输出稳定并准备好传播到下一个位置(在 图 7 中显示为“输出就绪”)。例如,ALU 的输出在下降沿就绪。在时钟值为 0 的持续时间内,ALU 的输出传播到寄存器文件输入。在下一个时钟周期,上升沿表示寄存器文件输入值已准备好写入寄存器(在 图 7 中显示为“新输入”)。
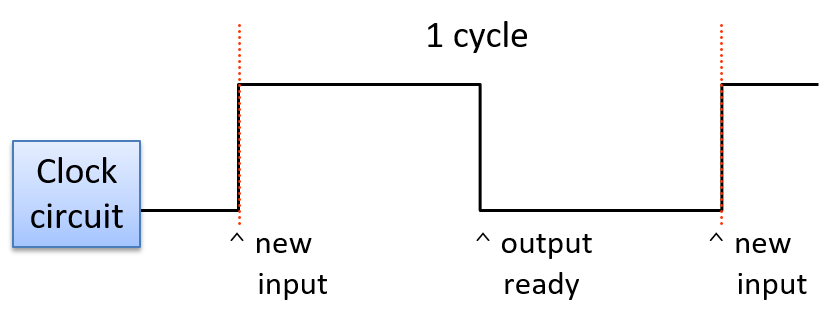
图 7. 新时钟周期的上升沿触发其控制的电路输入的变化。当其控制的电路输出有效时,下降沿触发。
时钟周期(或时钟速率)的长度受指令执行任何阶段的最长传播延迟限制。执行阶段和通过 ALU 的传播通常是最长的阶段。因此,时钟周期时间的一半不得快于 ALU 输入值通过最慢操作电路传播到 ALU 输出所需的时间(换句话说,输出反映了对输入的操作结果)。例如,在我们的四操作 ALU(OR、ADD、AND 和 EQUALS)中,行波进位加法器电路具有最长的传播延迟,并决定了时钟周期的最小长度。
由于完成 CPU 指令执行的一个阶段需要一个时钟周期,因此具有四阶段指令执行序列(获取、解码、执行、写回;参见图 8)的处理器每四个时钟周期最多完成一条指令。

图 8. 四阶段指令执行需要四个时钟周期才能完成。
例如,如果时钟频率为 1 GHz,则一条指令需要 4 纳秒才能完成(四个阶段中的每个阶段都需要 1 纳秒)。如果时钟频率为 2 GHz,则一条指令仅需 2 纳秒即可完成。
虽然时钟频率是影响处理器性能的一个因素,但时钟频率本身并不是衡量处理器性能的有效指标。相反,在程序完整执行过程中测得的平均每条指令的周期数 (CPI) 是衡量 CPU 性能的更好标准。通常,处理器无法在整个程序执行过程中保持其最大 CPI。次最大 CPI 是多种因素造成的,包括执行改变控制流的常见程序结构,例如循环、if-else 分支和函数调用。运行一组标准基准测试程序的平均 CPI 用于比较不同的架构。CPI 是衡量 CPU 性能的更准确指标,因为它衡量的是 CPU 执行程序的速度,而不是衡量单个指令执行的一个方面。有关处理器性能以及如何设计处理器以提高其性能的更多详细信息,请参阅计算机架构教科书1。
5.6.2. 把所有部件组合在一起:整台计算机中的 CPU
数据路径(ALU、寄存器文件以及连接它们的总线)和控制路径(指令执行电路)组成了 CPU。它们共同实现了冯·诺依曼架构的处理和控制部分。当今的处理器是作为蚀刻在硅片上的数字电路实现的。处理器芯片还包括一些快速的片上缓存存储器(使用锁存器存储电路实现),用于将最近使用的程序数据和指令的副本存储在靠近处理器的位置。有关片上缓存存储器的更多信息,请参阅 存储和内存层次结构章节 。
图 9 展示了完整的现代计算机环境中处理器的示例,其组件共同实现了冯·诺依曼架构。
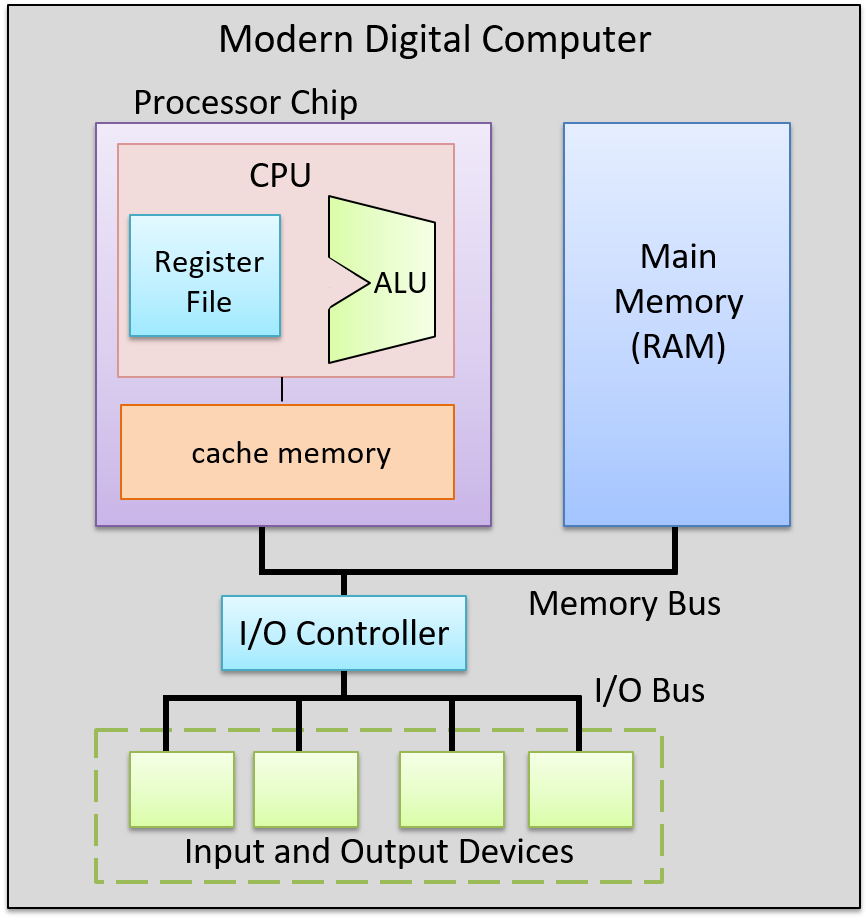
图 9. 现代计算机中的 CPU。总线连接处理器芯片、主内存以及输入和输出设备。
5.6.3. 脚注
- One suggestion is “Computer Architecture: A Quantitative Approach”, by John Hennessy and David Patterson.